MLP: Multi-Layer Perceptron or FFN: Feed Forward Netwok
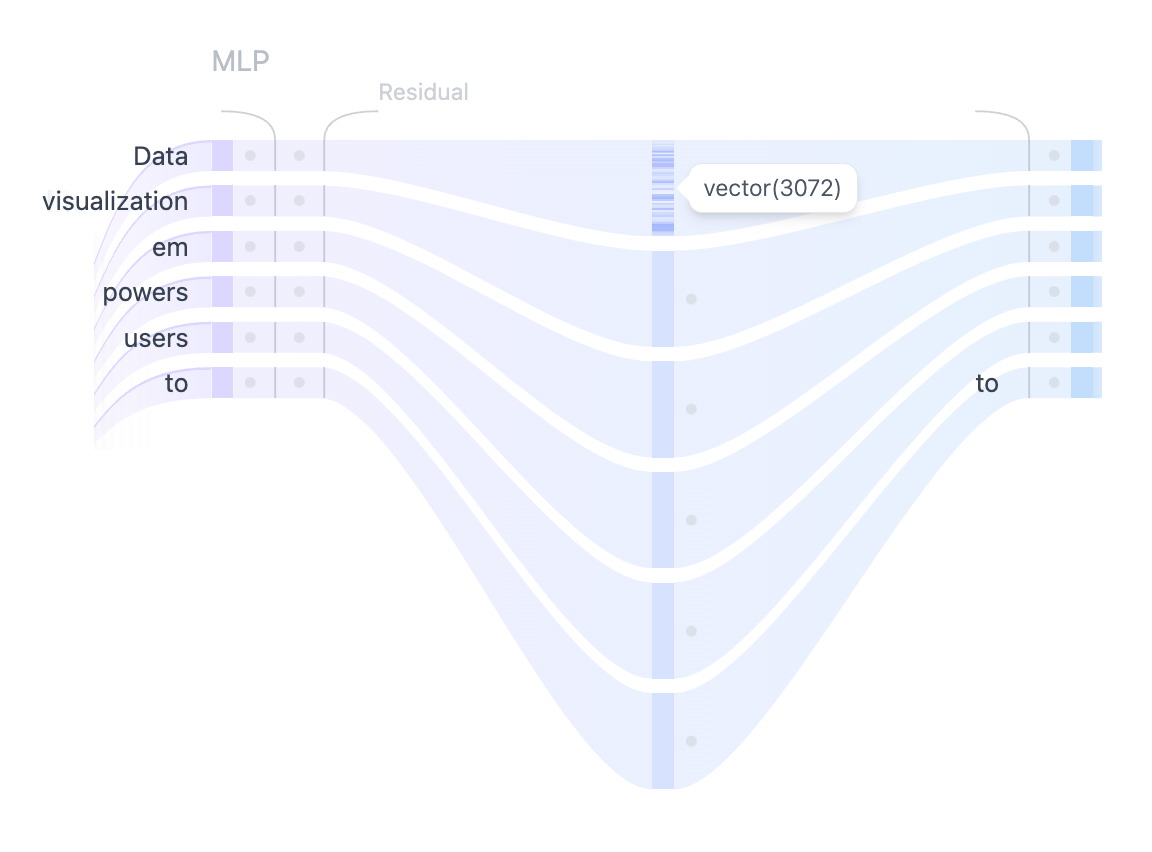
Figure 4. Using MLP layer to project the self-attention representations into higher dimensions to enhance the model’s representational capacity.
After the multiple heads of self-attention capture the diverse relationships between the input tokens, the concatenated outputs are passed through the Multilayer Perceptron (MLP) layer to enhance the model’s representational capacity. The MLP block consists of two linear transformations with a GELU activation function in between. The first linear transformation increases the dimensionality of the input four-fold from 768 to 3072. The second linear transformation reduces the dimensionality back to the original size of 768, ensuring that the subsequent layers receive inputs of consistent dimensions. Unlike the self-attention mechanism, the MLP processes tokens independently and simply map them from one representation to another.
Why projected to a higher dimension and back?